afl-challenges
本文最后更新于:2023年10月17日 晚上
afl-challenges
这篇文章笔者将通过afl-training的几个示例,来了解如何对真实程序进行fuzz。
libxml2
libxml2库是解析XML文档的函数库。它用 C 语言写成,并且能被多种语言所调用。我们fuzz的目标是找到libxml2的历史CVE。
根据afl-training下载对应版本的libxml2:
1 | |
进行编译:(编译时python版本要 <= 3.8)
1 | |
根据官方文档,编写定制的harness。
1 | |
这里选择libxml2官方提供的几个api进行fuzz。
然后编译。
1 | |
创建种子文件。
1 | |
种子文件只要是xml格式即可,不必拘泥于内容。
示例如下:
1 | |
启动fuzzer。
1 | |
这里笔者运气也是有点小衰,跑半天没跑出来洞。
如何提高fuzz的运行效率,主要有以下方式:
- 使用更有效地xml样本,可以使用
-x参数采用字典的形式。 - 使用
while (__AFL_LOOP(1000)) { ... }格式,减少不断fork带来的损失。 - 并行进行fuzz。
- 改进
harness。
这里笔者就不改进harness了,采用字典+并行的方式运行fuzzer。
这里的字典是afl官方自带的,使用-m none解除对fuzzer内存的限制,采用四核并行运行的方式。
1 | |
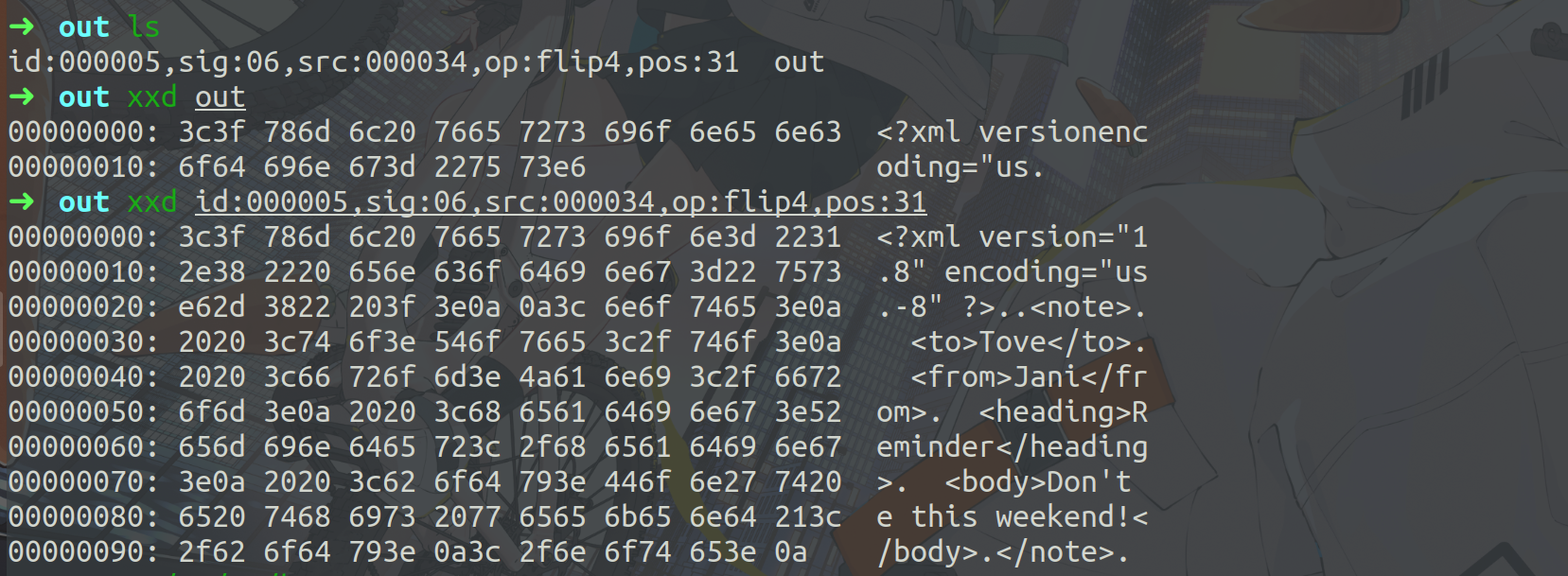
这里,笔者跑出了很多的crash,运行harness,简单验证下。
发现是一个堆溢出漏洞,溢出了一个字节。
查看源码。
1 | |
这里应该是MOVETO_ENDTAG宏对指针的检查不严格,造成指针越界了。笔者也不详细分析漏洞了。
笔者又看了几个crash,发现都是一样的漏洞。
这里也就不一个一个看了,使用afl-utils提供的工具afl-collect进行漏洞整理,这个工具可以很方便的对并行的fuzz结果进行整理,并标记漏洞是否可以利用。
1 | |
这里一共跑出了67个漏洞,但都是一样的,也就是上面描述的洞。
我们也可以使用afl-cmin和afl-tmin对结果进行精简。
afl-cmin 最小化输入数量。有些输入能够覆盖的路径是一样的,只需要保存一个就行,可以减少样本数量。
afl-tmin 最小化输入大小。有些样本输入是冗余的,删除部分也可以造成 crash,可以将输入的样本精简。值得一提的是,afl-tmin只能对单个文件进行分析。
使用afl-tmin减少样本数量。
结果与afl-collect一样,仅保留了一个样本。
使用afl-tmin减小样本大小。
可以看到,精简后的样本确实是小了不少。
这里,我们还想找到其它的漏洞,为了避免这个漏洞对我们fuzz功能产生影响。
我们在原始漏洞的基础上打个patch,直接在源码上修改即可。
1 | |
还是一样的过程,编译然后运行fuzzer。
这次运行的时间就比较长了,然后也没有找的很多的漏洞。
直接使用afl-collect对crash进行分析。
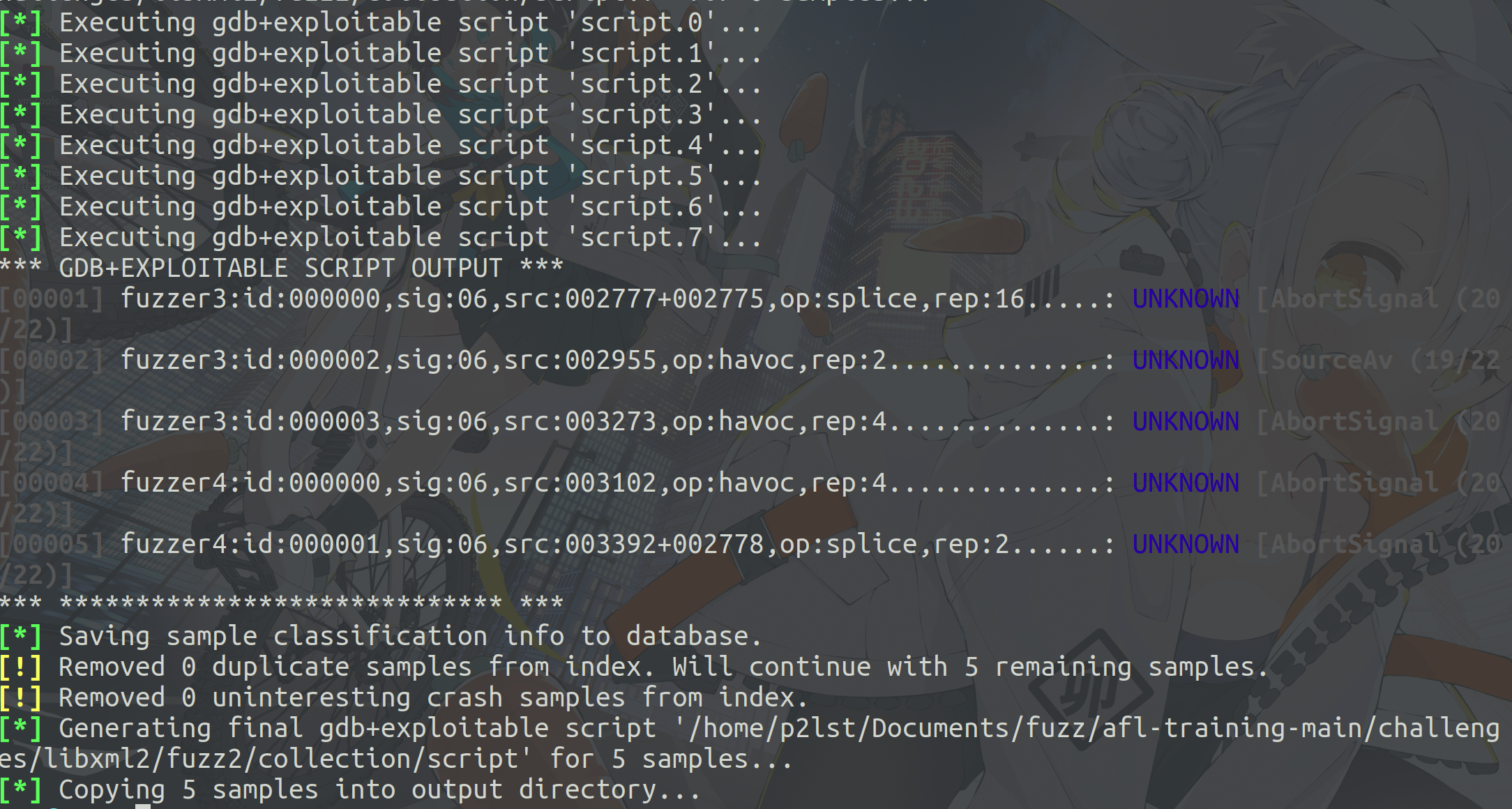
运行harness进行漏洞验证。
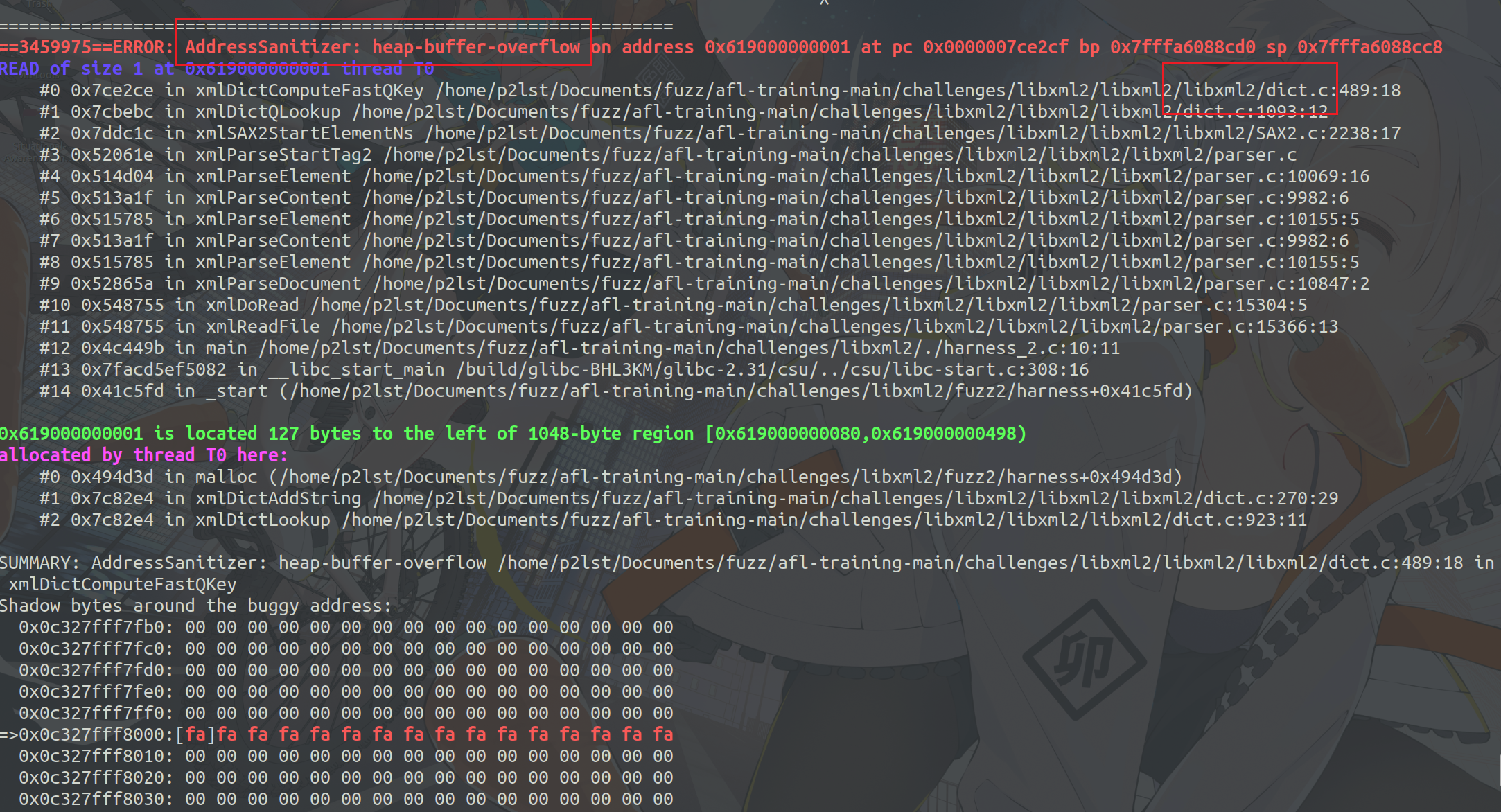
还是一个堆溢出漏洞。
查看源码。
1 | |
可以看到,这里并没有对数组下标进行约束,存在数组溢出漏洞。
ntpq
ntpq 是 NTP 参考实现工具套件中的一个实用程序。它查询服务器(如 ntpd)并向用户提供信息。
我们此次的目标是使用fuzzer找到CVE-2009-0159。
先下载ntpq源码:
1 | |
然后编译:
1 | |
需要注意的是,我们这次测试的程序并不是简单的从标准输入或者文件中获取输入的,而是一个网络收发包程序。测试这类程序,我们一般会进行隔离测试。通常来说,解析器等目标函数通常可以很容易地进行隔离测试。所以,我们这次采取的措施是对目标函数cookedprint进行针对性的fuzz。其中的 datatype, status 和 data 都从 stdin 读入,输出文件为 stdout。
其函数原型如下:
1 | |
这里,我们直接替换ntpq/ntqp.c的main函数,并使用persistent mode加快fuzz进程。
最终形成的harness如下所示:
1 | |
将上述代码写入到main函数中,并重新编译。
1 | |
1 | |
创建种子文件与输出文件。
1 | |
启动fuzzer,使用字典模式。
1 | |
跑了将近5分钟,我们就跑出来了上百个crashes了。不得不说,效率真的很高。
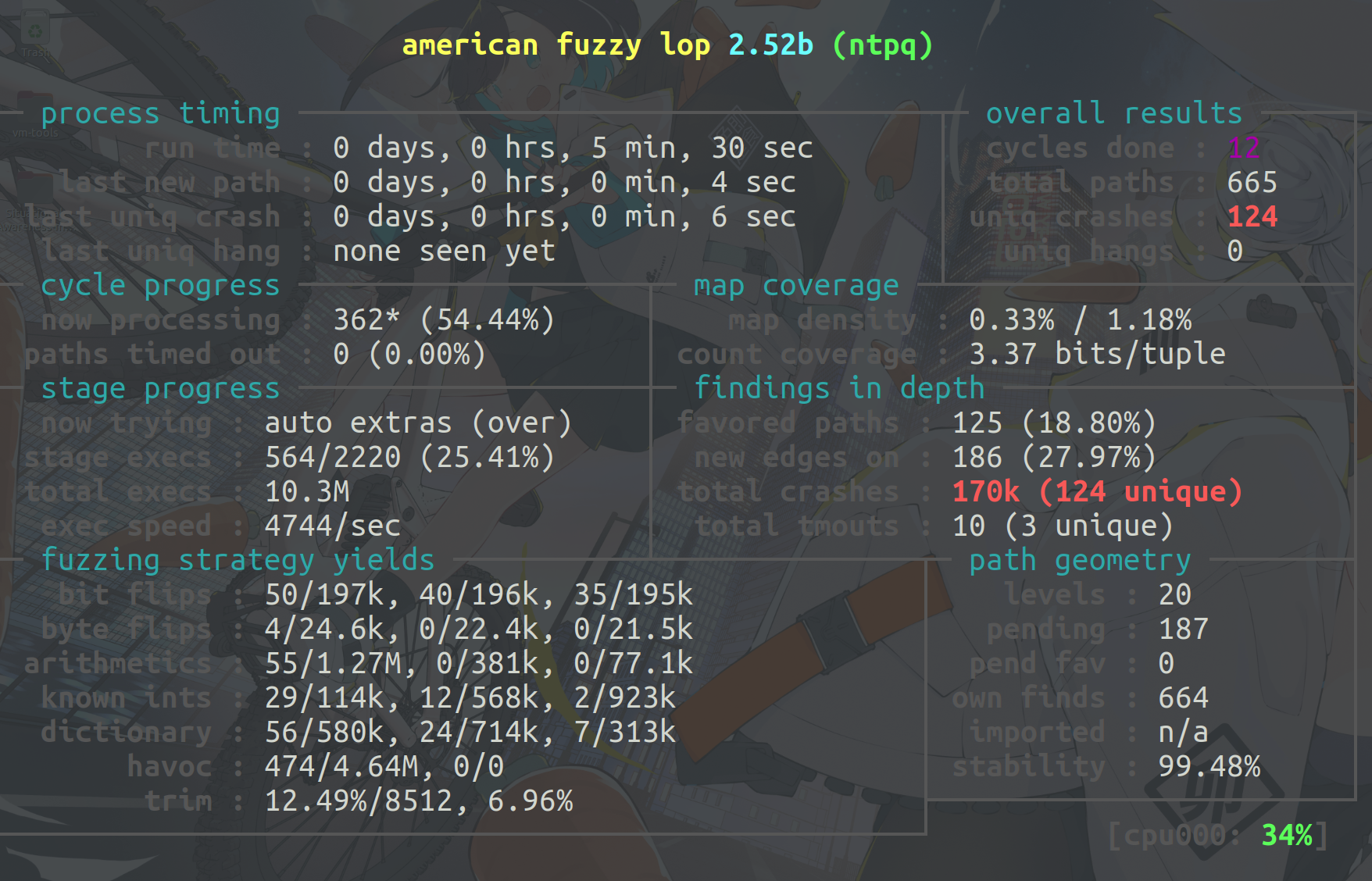
我们使用afl-collect对crashes做一个简单的整理。
1 | |
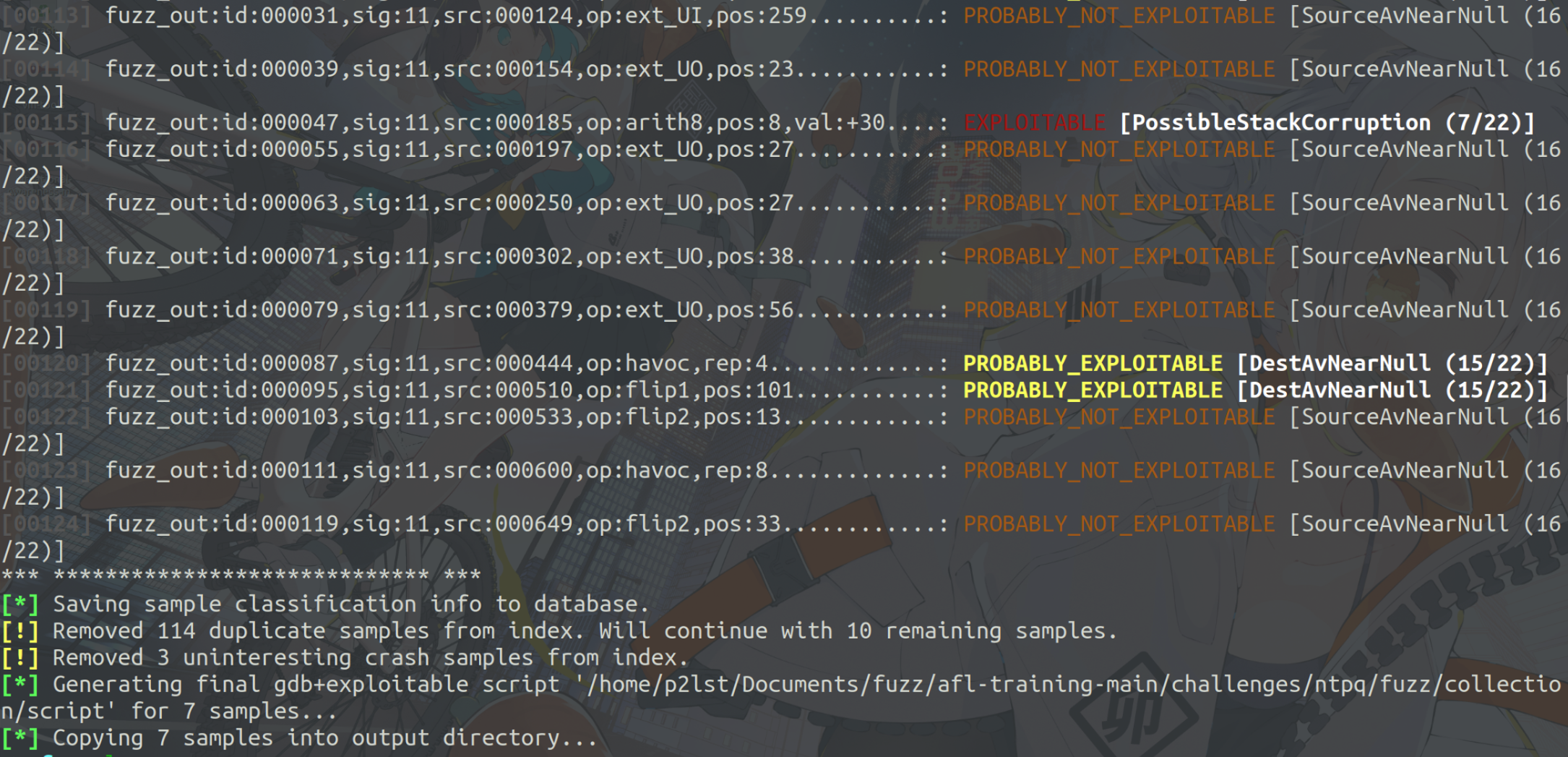
最终,只剩下了7个crashes。
到目前为止,仅仅出现crashes已经满足不了我们了。我们想查看代码覆盖率(针对cookedprint函数),这个具体要怎么实现呢?
可以使用llvm中对gcov的支持来查看代码覆盖率。
简单来说gcov是一个测试代码覆盖率的工具。与GCC(llvm也支持)一起使用来分析程序,以帮助创建更高效、更快的运行代码,并发现程序的未测试部分。这是一个命令行方式的控制台程序,需要结合lcov,gcovr等前端图形工具才能实现统计数据图形化。
这里我们重新编译支持gcov的ntpq。
1 | |
然后调用ntpq运行fuzz_out/queue目录下所有的文件,即可记录代码所有覆盖的路径。
这里,我们写一个简单的shell脚本。
1 | |
生成gcov报告:
1 | |

覆盖率信息保存到了ntqp.c.gcov文件中。
查看该文件,并重点关注cookedprint函数。
其中前面是-的表示是没有对应生成代码的区域;前面是数字的表示执行了的次数;前面是#####的表示是没有执行到的代码,可以通过观察覆盖率然后调整种子提升模糊测试效率。
1 | |
总结
通过对afl-training的学习,了解了afl常用的命令,以及常用工具的使用方式。同时,学到了不同输入方式下harness的编写,也就是想办法把非标准输入改为标准输入或者文件输入的形式。harness是fuzz的核心,一定要对测试程序写出针对性的harness。之后,笔者也会学习如何针对性的写出harness,继续加油吧。
参考文档:
https://tttang.com/archive/1508/
https://blog.wingszeng.top/afl-training-challenge-1-libxml2/
https://mundi-xu.github.io/2021/03/12/Start-Fuzzing-and-crashes-analysis/